
Introduction
The Rise of Enterprise RAG Systems
Large language models have transformed how businesses interact with information, automate workflows, and deliver digital experiences. However, many organisations quickly discover that standalone AI models struggle when they need access to proprietary knowledge, current business information, or domain-specific expertise.
This is where RAG Development (Retrieval-Augmented Generation) has emerged as one of the most important areas of enterprise AI engineering.
Rather than relying solely on the information used during model training, RAG systems retrieve relevant information from trusted knowledge sources and provide that context to the AI model before generating a response. This approach helps organisations build AI applications that are more accurate, transparent, secure, and aligned with business requirements.
As enterprises increasingly adopt AI across customer support, internal knowledge management, compliance, legal research, and operational workflows, RAG Development has become a critical capability for building production-ready AI systems.
Businesses investing in RAG Development initiatives are increasingly prioritising security, accuracy, and long-term scalability.
In this guide, we’ll explore how Retrieval-Augmented Generation works, the technologies involved, architectural considerations, security requirements, development costs, and best practices for building enterprise-grade RAG applications in 2026.
What You’ll Learn
By the end of this guide, you’ll understand:
-
What Retrieval-Augmented Generation (RAG) is and why it has become a core enterprise AI architecture
-
Why traditional LLM applications often struggle in production environments
-
How modern RAG systems retrieve, process, and generate grounded responses
-
The role of vector databases, embeddings, and retrieval pipelines
-
Security, governance, and compliance considerations for enterprise deployments
-
Typical development costs, timelines, and implementation challenges
-
Common mistakes that reduce accuracy and user trust
-
How to evaluate and choose the right RAG Development partner
What Is Retrieval-Augmented Generation (RAG)?
Retrieval-Augmented Generation (RAG) is an AI architecture that combines large language models (LLMs) with external knowledge retrieval systems to generate more accurate, relevant, and up-to-date responses.
Unlike traditional AI applications that rely solely on information contained within a model’s training data, RAG systems retrieve information from trusted data sources before generating an answer. This allows the AI to reference current business information, proprietary documents, knowledge bases, and domain-specific content that would otherwise be unavailable to the model.
In simple terms, RAG enables AI systems to “look up” relevant information before responding.
This approach has become increasingly important for enterprises because business knowledge changes constantly. Product documentation, policies, customer records, compliance requirements, and internal procedures evolve over time, making static AI models insufficient for many real-world use cases.
How RAG Differs from Traditional LLM Applications
Traditional large language models generate responses based on patterns learned during training. While these models are highly capable, they face several limitations:
-
They cannot access private company knowledge by default
-
Their information may become outdated over time
-
They can generate inaccurate or fabricated responses (hallucinations)
-
They often struggle with highly specialised business information
RAG addresses these challenges by retrieving relevant information from external sources and providing that context to the model before response generation.
How Retrieval-Augmented Generation Works
At a high level, a RAG system follows a simple workflow:
-
A user submits a question.
-
The system converts the query into vector embeddings.
-
A vector database searches for the most relevant content.
-
Relevant documents or knowledge snippets are retrieved.
-
Retrieved information is provided to the language model.
-
The model generates a grounded response based on the retrieved context.
The result is a response that is significantly more accurate, explainable, and aligned with enterprise knowledge sources.
Why RAG Has Become the Preferred Enterprise AI Architecture
Many organisations initially attempted to build AI solutions using standalone language models. While these systems performed well in demonstrations, they often struggled in production environments where accuracy, compliance, security, and access to current information were critical.
As a result, RAG Development has become one of the most widely adopted approaches for enterprise AI initiatives. It enables businesses to leverage the capabilities of modern language models while maintaining control over their own knowledge, data governance, and security requirements.
Today, Retrieval-Augmented Generation is used across customer support, internal knowledge management, legal research, compliance workflows, financial services, healthcare applications, and AI-powered enterprise search systems.
Why Traditional LLM Applications Fail
Large language models have demonstrated remarkable capabilities across a wide range of tasks, from content generation and summarisation to coding assistance and customer support.
However, many organisations discover that deploying a standalone LLM is very different from building a reliable enterprise AI system.
While traditional LLM applications can perform well in controlled demonstrations, they often struggle when exposed to real-world business requirements involving accuracy, security, compliance, and access to proprietary knowledge.
Understanding these limitations is essential for organisations planning long-term AI initiatives.
Limited Access to Business Knowledge
One of the biggest challenges with standalone language models is their inability to access private company information by default.
Most organisations store valuable knowledge across:
-
Internal documentation
-
Knowledge bases
-
CRM systems
-
Product manuals
-
Policy documents
-
Compliance records
-
Customer support content
Traditional LLMs cannot automatically access this information unless it is provided as context.
As a result, responses may be incomplete, outdated, or disconnected from the organisation’s actual knowledge sources.
Hallucinations and Inaccurate Responses
Large language models are designed to predict the most likely next token rather than verify factual accuracy.
This means they can occasionally generate information that appears convincing but is factually incorrect.
These hallucinations may include:
-
Incorrect procedures
-
Non-existent policies
-
Fabricated references
-
Inaccurate technical guidance
-
Misleading business information
In enterprise environments, even small inaccuracies can create operational, legal, or reputational risks.
Outdated Information
Language models are trained on data available at a specific point in time.
Once training is complete, the model does not automatically learn new information.
This creates challenges for organisations where information changes frequently, including:
-
Product updates
-
Internal processes
-
Regulatory requirements
-
Pricing structures
-
Support documentation
-
Industry standards
Without access to current information, AI responses can quickly become outdated.
Lack of Source Transparency
Enterprise users increasingly expect AI systems to explain where information originates.
Traditional LLM applications typically generate answers without providing clear evidence or references.
This creates challenges when users need to:
-
Verify information
-
Audit decisions
-
Confirm compliance requirements
-
Review supporting documentation
Without traceable sources, trust in AI-generated responses can decline significantly.
Poor Compliance and Governance Support
Many industries operate under strict regulatory and compliance requirements.
Examples include:
-
Financial services
-
Healthcare
-
Legal services
-
Government organisations
-
Insurance providers
Traditional AI systems often struggle to meet governance requirements because they lack mechanisms for controlling data access, auditing responses, and enforcing information boundaries.
No Document-Level Access Control
Enterprise knowledge is rarely accessible to every employee.
Different users often require different levels of access based on their roles and responsibilities.
Examples include:
-
Human resources records
-
Financial reports
-
Legal contracts
-
Executive communications
-
Customer information
Traditional LLM applications generally lack the ability to enforce granular permissions across multiple knowledge sources.
This creates significant security and governance concerns.
Difficulty Scaling Across the Organisation
Many businesses begin with simple AI pilots before expanding usage across departments.
As adoption grows, organisations often encounter challenges such as:
-
Inconsistent information quality
-
Duplicate knowledge repositories
-
Access control requirements
-
Compliance obligations
-
Performance limitations
Systems that perform well for small demonstrations may not be suitable for enterprise-wide deployment.
The Enterprise AI Gap
These limitations create what many organisations describe as the enterprise AI gap.
The gap exists between what a general-purpose language model can do and what businesses actually require from production AI systems.
Enterprises need AI that is:
-
Accurate
-
Explainable
-
Secure
-
Auditable
-
Current
-
Aligned with organisational knowledge
Traditional LLM applications alone are often unable to satisfy all of these requirements.
Why RAG Solves These Challenges
Retrieval-Augmented Generation was developed specifically to address many of the limitations associated with standalone language models.
By retrieving information from trusted knowledge sources before generating responses, RAG systems can:
-
Reduce hallucinations
-
Improve factual accuracy
-
Access current information
-
Provide source transparency
-
Support governance requirements
-
Enforce access controls
-
Improve enterprise trust
This is one of the primary reasons why RAG Development has become a preferred architecture for organisations seeking to move beyond AI experimentation and into production-ready enterprise deployments.
Rather than replacing large language models, RAG enhances them by connecting AI capabilities with the information businesses rely on every day.
How RAG Systems Work
At a high level, a Retrieval-Augmented Generation (RAG) system combines information retrieval with large language model reasoning.
Instead of asking a language model to answer questions using only its training data, a RAG system first retrieves relevant information from trusted knowledge sources and then provides that information to the model as context.
This process allows AI applications to generate responses that are grounded in current, organisation-specific knowledge rather than relying solely on general training data.
The RAG Workflow
A typical RAG system follows a sequence of steps:
-
A user submits a question.
-
The query is converted into vector embeddings.
-
The system searches a vector database for relevant content.
-
Matching documents or knowledge snippets are retrieved.
-
Retrieved information is passed to the language model.
-
The model generates a grounded response.
-
The response is returned to the user.
This workflow helps ensure answers are based on relevant information rather than assumptions.
Step 1: User Query Processing
Every RAG workflow begins with a user query.
Examples may include:
-
“What is our refund policy?”
-
“Summarise the latest compliance requirements.”
-
“How does our onboarding process work?”
-
“Show me the implementation guide for this feature.”
The system first analyses the query and prepares it for retrieval.
In modern RAG architectures, understanding user intent is just as important as finding matching keywords.
Step 2: Generating Embeddings
The user’s question is converted into numerical representations known as embeddings.
Embeddings capture the semantic meaning of text rather than simply matching exact words.
For example, a system can understand that:
-
“Customer support” and “help desk”
-
“Invoice” and “billing document”
-
“Employee handbook” and “company policy”
may be closely related concepts.
This allows retrieval systems to find relevant information even when different terminology is used.
Step 3: Searching the Vector Database
Once embeddings are generated, the system searches a vector database.
Unlike traditional databases, vector databases are designed to identify information based on similarity rather than exact matches.
Popular vector databases include:
-
Pinecone
-
Weaviate
-
Qdrant
-
pgvector
The objective is to retrieve content that is most relevant to the user’s question.
Step 4: Retrieving Relevant Context
The retrieval layer selects the most relevant documents, passages, or knowledge fragments.
These may come from:
-
Internal documentation
-
Product manuals
-
Knowledge bases
-
Support articles
-
CRM systems
-
Compliance repositories
-
Company policies
The quality of retrieved context is one of the most important factors affecting overall system performance.
Even the most advanced language model cannot generate accurate answers if the retrieval process provides poor information.
Step 5: Augmenting the Prompt
The retrieved information is added to the prompt before being sent to the language model.
This process is known as augmentation.
Rather than relying solely on pre-trained knowledge, the model receives:
-
User question
-
Relevant company information
-
Supporting context
-
Reference material
The model can then generate responses based on verified information.
Step 6: Response Generation
The language model processes the augmented prompt and generates a response.
Because the model has access to retrieved context, answers are generally:
-
More accurate
-
More relevant
-
Better aligned with business knowledge
-
Easier to verify
This significantly reduces the likelihood of hallucinations compared to standalone LLM applications.
Step 7: Source Attribution and Verification
Many enterprise RAG systems include source attribution capabilities.
This allows users to see:
-
Which documents were used
-
Where information originated
-
Supporting references
-
Related knowledge sources
Source transparency improves trust and helps organisations meet governance and compliance requirements.
Why Retrieval Quality Matters
A common misconception is that the language model is the most important component of a RAG system.
In practice, retrieval quality often has a greater impact on user experience than the choice of model itself.
Poor retrieval can lead to:
-
Missing information
-
Incorrect answers
-
Irrelevant responses
-
Reduced user confidence
Strong retrieval pipelines are therefore a core focus of successful RAG Development projects.
The Enterprise Advantage of RAG
By combining retrieval systems with language models, organisations gain the ability to deliver AI experiences that remain connected to their own knowledge and business processes.
This allows enterprises to:
-
Improve answer accuracy
-
Reduce hallucinations
-
Access current information
-
Protect sensitive data
-
Maintain governance controls
-
Scale AI adoption across departments
As a result, RAG has become the foundation of many modern enterprise AI systems, powering everything from internal knowledge assistants to customer-facing support platforms and AI-powered search experiences.
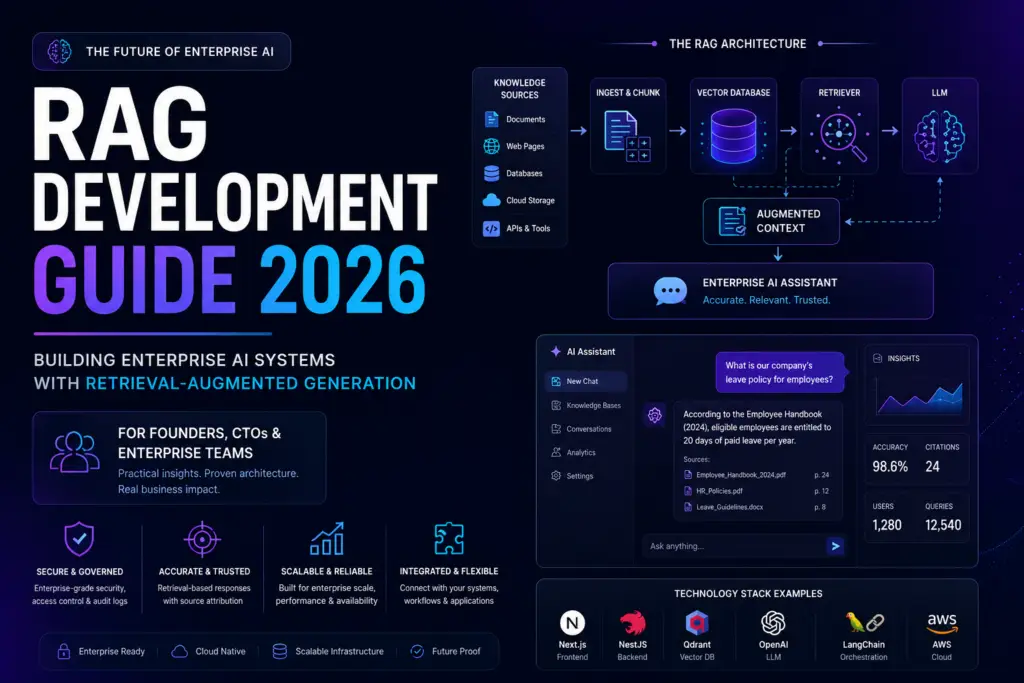
Core Components of a Modern RAG Architecture
A modern Retrieval-Augmented Generation system consists of multiple interconnected components working together to retrieve, process, and generate accurate responses.
While the user may only see a simple chat interface, enterprise-grade RAG systems rely on a sophisticated architecture that manages knowledge ingestion, semantic search, access control, retrieval quality, and AI response generation.
Understanding these components is essential for designing scalable and reliable AI systems.
Data Sources
Every RAG system begins with data.
The quality of responses generated by the AI is directly influenced by the quality, accuracy, and relevance of the underlying knowledge sources.
Common enterprise data sources include:
-
Internal documentation
-
Product manuals
-
Knowledge bases
-
Wikis
-
CRM systems
-
Customer support content
-
Policies and procedures
-
Contracts and legal documents
-
Databases
-
Websites and portals
Many organisations also integrate multiple repositories into a unified knowledge architecture to provide broader information coverage.
The objective is to ensure that the retrieval layer can access the information users need when generating responses.
Data Ingestion and Processing
Before documents can be searched efficiently, they must be prepared for retrieval.
This process typically includes:
-
Document extraction
-
Text cleaning
-
Metadata enrichment
-
Chunking
-
Indexing
Chunking is particularly important because large documents are generally divided into smaller sections that can be retrieved more accurately during search operations.
Well-designed ingestion pipelines significantly improve retrieval quality and overall system performance.
Embedding Models
Embedding models convert text into numerical representations known as vectors.
These vectors capture the semantic meaning of content and enable similarity-based search.
Rather than searching for exact keyword matches, embeddings allow systems to identify content that is conceptually related.
Popular embedding models include:
-
OpenAI Embeddings
-
Voyage AI
-
BGE Models
-
E5 Models
-
Cohere Embeddings
The choice of embedding model can have a significant impact on retrieval accuracy and search quality.
Vector Databases
Vector databases store embeddings and enable high-performance similarity search.
When a user submits a query, the system compares the query embedding against stored document embeddings to identify relevant information.
Popular vector database platforms include:
-
Pinecone
-
Weaviate
-
Qdrant
-
Milvus
-
pgvector
Each platform offers different advantages depending on scalability requirements, deployment preferences, and operational complexity.
For many enterprise projects, vector databases serve as the foundation of the retrieval layer.
Retrieval Layer
The retrieval layer is responsible for identifying the most relevant content for a given query.
Its responsibilities include:
-
Semantic search
-
Filtering
-
Ranking
-
Access control enforcement
-
Context selection
Retrieval quality often determines whether a RAG system succeeds or fails.
Even the most advanced language models cannot compensate for poor retrieval results.
For this reason, retrieval engineering has become a major focus area within enterprise RAG Development projects.
Large Language Model Layer
Once relevant information has been retrieved, the language model generates a response.
Popular model providers include:
-
OpenAI
-
Anthropic
-
Google
-
Meta
-
Mistral
The model receives:
-
User query
-
Retrieved context
-
Instructions
-
System prompts
and generates a response grounded in the retrieved information.
The language model provides reasoning and natural language generation capabilities, while the retrieval system provides factual grounding.
Many enterprise AI platforms also require robust LLM Integration capabilities to connect securely with commercial and open-source language models while maintaining reliability, scalability, and governance controls.
Orchestration Layer
Enterprise RAG systems often require orchestration frameworks to coordinate different components.
The orchestration layer manages:
-
Query processing
-
Retrieval workflows
-
Prompt construction
-
Model interactions
-
Tool usage
-
Error handling
Popular orchestration frameworks include:
-
LangChain
-
LlamaIndex
-
Haystack
These frameworks help simplify development and improve maintainability as systems grow in complexity.
Security and Access Control Layer
Enterprise environments require strict control over information access.
Security controls commonly include:
-
Authentication
-
Role-based access control
-
Document-level permissions
-
Encryption
-
Audit logging
-
Data governance policies
Without these controls, sensitive information may be exposed to unauthorised users.
Security should therefore be treated as a core architectural component rather than an afterthought.
Monitoring and Evaluation Layer
Modern RAG systems require continuous monitoring and evaluation.
Key metrics often include:
-
Retrieval accuracy
-
Response quality
-
Latency
-
User satisfaction
-
Citation accuracy
-
System reliability
Monitoring enables teams to identify weaknesses, improve performance, and maintain trust in AI-generated responses.
Bringing Everything Together
A successful RAG system is much more than a language model connected to a vector database.
Enterprise-grade architectures combine data pipelines, embeddings, retrieval systems, orchestration frameworks, security controls, and monitoring capabilities into a unified platform.
When these components work together effectively, organisations can build AI systems that are accurate, scalable, secure, and aligned with business objectives.
Many advanced AI Agents are built on top of RAG architectures, enabling them to retrieve business knowledge, reason over information, and execute tasks using trusted enterprise data.
This architecture has become the foundation for many modern AI applications, including enterprise search, knowledge assistants, customer support systems, compliance tools, and AI-powered productivity platforms.
Enterprise Use Cases for RAG Development
The adoption of Retrieval-Augmented Generation is being driven by practical business outcomes rather than technology trends alone.
Organisations across industries are using RAG systems to improve knowledge accessibility, increase operational efficiency, reduce support workloads, and enhance decision-making.
Because RAG architectures can connect AI models to trusted organisational knowledge, they are particularly well suited to enterprise environments where accuracy, security, and governance are critical requirements.
Below are some of the most common enterprise use cases for RAG Development in 2026.
Customer Support Knowledge Assistants
Customer support teams often manage large volumes of documentation, product information, troubleshooting guides, and policy content.
RAG-powered support assistants can:
-
Retrieve relevant support articles
-
Answer customer questions
-
Surface troubleshooting procedures
-
Assist support agents during conversations
-
Reduce ticket resolution times
Rather than relying on static chatbot responses, RAG systems generate answers using current product knowledge and support documentation.
Internal Knowledge Management
Many organisations struggle with information scattered across multiple systems.
Employees frequently spend valuable time searching for:
-
Internal policies
-
Technical documentation
-
Process guides
-
Training materials
-
Project documentation
RAG-powered knowledge assistants enable employees to access information through natural language queries, significantly improving productivity and knowledge discovery.
Enterprise Search Platforms
Traditional enterprise search systems often rely heavily on keyword matching.
RAG-based search systems improve this experience by understanding the intent behind user questions and retrieving relevant information based on meaning rather than exact keywords.
Benefits include:
-
Improved search accuracy
-
Faster information discovery
-
Better user experiences
-
Reduced information silos
This has made RAG a popular foundation for next-generation enterprise search platforms.
Compliance and Regulatory Systems
Industries with strict regulatory requirements often maintain large collections of compliance documentation.
RAG systems can help teams:
-
Search regulatory content
-
Review compliance procedures
-
Access policy documentation
-
Understand operational requirements
-
Support audit preparation
Because responses are grounded in approved documentation, compliance teams can access information more efficiently while maintaining governance controls.
Legal Research and Contract Analysis
Legal teams manage large volumes of contracts, regulations, policies, and case-related documentation.
RAG-powered legal assistants can:
-
Retrieve relevant clauses
-
Summarise agreements
-
Search legal repositories
-
Analyse policy documentation
-
Accelerate legal research workflows
These systems help improve efficiency while ensuring responses remain connected to approved legal content.
Financial Services and Banking
Financial institutions increasingly use RAG architectures to improve access to operational and regulatory knowledge.
Common applications include:
-
Internal knowledge assistants
-
Regulatory research
-
Risk management support
-
Customer service automation
-
Policy retrieval
Because financial organisations often operate within highly regulated environments, security and access controls are particularly important.
Healthcare Knowledge Systems
Healthcare organisations manage large amounts of clinical, operational, and regulatory information.
RAG applications can support:
-
Clinical knowledge search
-
Policy retrieval
-
Medical documentation access
-
Internal training systems
-
Administrative workflows
Healthcare deployments typically require strict governance controls to protect sensitive information and comply with privacy requirements.
SaaS Product Copilots
Software companies are increasingly embedding AI capabilities directly into their products.
RAG-powered copilots can:
-
Answer product questions
-
Guide users through workflows
-
Surface relevant documentation
-
Provide onboarding assistance
-
Improve self-service experiences
These systems help reduce support workloads while improving user satisfaction.
Many modern AI SaaS Development projects now include RAG capabilities as a core feature rather than an optional enhancement.
AI Agents Powered by Enterprise Knowledge
Many advanced AI Agents depend on RAG architectures to access organisational knowledge and make informed decisions.
Rather than operating in isolation, these systems can:
-
Retrieve relevant business information
-
Understand organisational policies
-
Access approved documentation
-
Support workflow automation
-
Assist with decision-making
This combination of retrieval and reasoning enables more capable and trustworthy AI systems.
Executive and Decision Support Systems
Business leaders often require access to information spread across multiple departments and systems.
RAG-powered executive assistants can help:
-
Summarise reports
-
Retrieve operational data
-
Surface key business information
-
Accelerate decision-making
-
Improve organisational visibility
These systems enable leaders to access information more efficiently without navigating multiple platforms.
Why Enterprise Adoption Continues to Grow
The demand for enterprise AI is growing rapidly, but organisations increasingly recognise that standalone language models are rarely sufficient for production use cases.
RAG Development provides a practical framework for connecting AI capabilities with trusted business knowledge, enabling organisations to deploy systems that are more accurate, secure, explainable, and aligned with operational requirements.
As a result, Retrieval-Augmented Generation has become one of the most widely adopted architectures for enterprise AI initiatives across industries including finance, healthcare, legal services, manufacturing, technology, and professional services.
Designing a Secure Enterprise RAG System
Security is one of the most important considerations in enterprise AI Development, particularly when systems interact with sensitive organisational knowledge.
While Retrieval-Augmented Generation systems provide significant advantages over standalone language models, they also introduce new security, governance, and compliance challenges that must be addressed during architecture and implementation.
Enterprise organisations often work with highly sensitive information including customer records, financial data, contracts, intellectual property, internal documentation, and operational procedures.
A secure RAG system must ensure that users can access the information they need while preventing unauthorised access to protected data.
For this reason, security should be treated as a core architectural requirement rather than a feature added after deployment.
Authentication and Identity Management
Every enterprise RAG system should begin with strong identity management controls.
Authentication systems help verify user identities before access is granted to knowledge repositories and AI services.
Common authentication approaches include:
-
Single Sign-On (SSO)
-
Multi-Factor Authentication (MFA)
-
OAuth
-
SAML
-
Enterprise identity providers
Integrating AI systems with existing identity infrastructure helps organisations maintain consistent security policies across the business.
Role-Based Access Control (RBAC)
Not all users should have access to the same information.
A secure RAG architecture should enforce role-based access controls that align with organisational responsibilities.
Examples include:
-
Employees
-
Managers
-
Human resources teams
-
Finance departments
-
Legal teams
-
Executive leadership
Users should only be able to retrieve information they are authorised to access.
This principle significantly reduces the risk of accidental data exposure.
Document-Level Security
Enterprise knowledge repositories often contain information with different security classifications.
Examples include:
-
Public documentation
-
Internal procedures
-
Confidential reports
-
Financial records
-
Legal agreements
-
Customer information
Document-level security ensures retrieval systems only return content that users are authorised to access.
Without document-level controls, sensitive information could be exposed through AI-generated responses.
Data Encryption
Encryption should be applied throughout the system.
This typically includes:
-
Data at rest
-
Data in transit
-
Backup storage
-
Vector databases
-
Knowledge repositories
Strong encryption helps protect sensitive information from unauthorised access and supports compliance requirements across multiple industries.
Protecting Personally Identifiable Information (PII)
Many organisations store information that contains personally identifiable information.
Examples include:
-
Customer records
-
Employee information
-
Contact details
-
Financial data
-
Healthcare information
RAG systems should include safeguards that prevent unauthorised access to sensitive personal information.
Techniques may include:
-
Data masking
-
Redaction
-
Access restrictions
-
Query filtering
-
Compliance policies
Protecting PII is particularly important for organisations operating under privacy regulations such as GDPR and other regional data protection frameworks.
Secure Knowledge Ingestion
Security begins long before users submit queries.
Knowledge ingestion pipelines should validate and process information carefully before it enters the retrieval system.
Best practices include:
-
Source verification
-
Malware scanning
-
Metadata validation
-
Access control mapping
-
Data classification
A secure ingestion process helps maintain knowledge quality while reducing operational risk.
Audit Logging and Monitoring
Enterprise AI systems should maintain detailed audit trails.
Audit logs help organisations track:
-
User activity
-
Retrieved documents
-
Administrative actions
-
Access attempts
-
Security events
-
System changes
Comprehensive logging supports governance, compliance, and incident investigation efforts.
Governance and Compliance
Many organisations operate within regulated environments.
Examples include:
-
Financial services
-
Healthcare
-
Insurance
-
Legal services
-
Government agencies
A secure RAG architecture should support:
-
Compliance reporting
-
Access reviews
-
Data retention policies
-
Governance controls
-
Security assessments
These controls help organisations deploy AI responsibly while meeting regulatory obligations.
Securing the Language Model Layer
Security considerations extend beyond retrieval systems.
Organisations should also evaluate:
-
Prompt injection attacks
-
Data leakage risks
-
Model misuse
-
Output validation
-
Third-party AI providers
Proper safeguards help ensure that language models operate within approved security boundaries.
Building Trust Through Security
Enterprise AI adoption depends heavily on trust.
Users must feel confident that information is accurate, protected, and governed appropriately.
A secure RAG system combines identity management, access controls, encryption, monitoring, governance, and operational processes into a unified security framework.
Organisations that prioritise security from the beginning are better positioned to scale AI adoption while maintaining compliance, protecting sensitive information, and building trust across the business.
For enterprises investing in RAG Development, security is not simply a technical requirement—it is a business requirement that directly influences adoption, governance, and long-term success.
Choosing the Right Vector Database
The vector database is one of the most important components of a modern RAG architecture.
Its primary responsibility is to store embeddings and retrieve the most relevant information when users submit queries.
The choice of vector database can influence:
-
Search performance
-
Scalability
-
Infrastructure complexity
-
Operational costs
-
Deployment flexibility
-
Security requirements
While there is no single solution suitable for every organisation, understanding the strengths and trade-offs of different platforms can help teams make informed architectural decisions.
What Is a Vector Database?
A vector database is designed to store and search vector embeddings.
Unlike traditional databases that rely primarily on exact matches or structured queries, vector databases identify information based on semantic similarity.
This allows RAG systems to retrieve information that is contextually relevant even when exact keywords are not present.
Vector databases are therefore a foundational component of enterprise RAG Development projects.
Pinecone
Pinecone is one of the most widely adopted managed vector database platforms.
It is designed to simplify infrastructure management while providing high-performance similarity search capabilities.
Advantages include:
-
Fully managed infrastructure
-
Fast deployment
-
High scalability
-
Minimal operational overhead
-
Enterprise support options
Best suited for:
-
Enterprise deployments
-
Fast-growing AI applications
-
Teams seeking managed infrastructure
Potential considerations:
-
Higher ongoing costs
-
Reduced infrastructure control compared to self-hosted solutions
Weaviate
Weaviate is an open-source vector database platform that supports both cloud and self-hosted deployments.
It offers extensive flexibility and supports hybrid search capabilities.
Advantages include:
-
Open-source foundation
-
Hybrid search support
-
Flexible deployment options
-
Strong ecosystem integration
Best suited for:
-
Enterprises requiring deployment flexibility
-
Organisations seeking greater infrastructure control
-
Hybrid search implementations
Potential considerations:
-
More operational complexity than fully managed platforms
Qdrant
Qdrant has become increasingly popular for enterprise AI applications due to its performance, simplicity, and open-source architecture.
Advantages include:
-
Open-source
-
Strong performance
-
Flexible deployment models
-
Developer-friendly architecture
-
Active community support
Best suited for:
-
Enterprise RAG systems
-
Custom AI applications
-
Teams seeking a balance between control and simplicity
Potential considerations:
-
Requires operational ownership for self-hosted environments
pgvector
pgvector extends PostgreSQL with vector search capabilities.
This approach allows organisations to manage structured data and vector embeddings within a single database platform.
Advantages include:
-
Familiar PostgreSQL ecosystem
-
Simplified architecture
-
Lower infrastructure complexity
-
Reduced operational overhead for smaller deployments
Best suited for:
-
Startups
-
MVP projects
-
Existing PostgreSQL environments
-
Smaller-scale RAG implementations
Potential considerations:
-
May not provide the same level of scalability as dedicated vector databases for very large deployments
Comparing Popular Vector Databases
| Platform | Best For | Deployment Model |
|---|---|---|
| Pinecone | Enterprise scale and managed infrastructure | Managed |
| Weaviate | Hybrid search and deployment flexibility | Managed or Self-Hosted |
| Qdrant | Enterprise RAG applications and open-source deployments | Managed or Self-Hosted |
| pgvector | PostgreSQL-based AI systems and MVPs | Self-Hosted or Managed PostgreSQL |
Factors to Consider When Choosing a Vector Database
When evaluating options, organisations should consider:
-
Expected data volume
-
Query performance requirements
-
Security requirements
-
Compliance obligations
-
Infrastructure expertise
-
Deployment preferences
-
Budget constraints
The ideal choice often depends on business priorities rather than technical specifications alone.
Enterprise Considerations
For enterprise environments, factors such as governance, access control, monitoring, and deployment flexibility are often just as important as raw search performance.
Decision-makers should evaluate how the vector database fits into the broader AI architecture, security model, and operational strategy.
A well-chosen vector database can simplify future scaling efforts and improve long-term maintainability.
Which Vector Database Should You Choose?
There is no universal answer.
Many startups begin with pgvector due to its simplicity and cost efficiency.
Growing organisations often adopt Qdrant or Weaviate to gain greater flexibility and retrieval capabilities.
Large enterprises frequently choose managed platforms such as Pinecone when operational simplicity and scalability are top priorities.
The most important objective is selecting a solution that aligns with current requirements while supporting future growth.
As enterprise AI adoption accelerates, vector databases will continue to serve as a critical foundation for Retrieval-Augmented Generation systems and advanced AI applications.
Advanced RAG Techniques
As enterprise AI adoption matures, organisations are increasingly moving beyond basic Retrieval-Augmented Generation implementations.
While a simple RAG architecture can significantly improve answer quality compared to standalone language models, enterprise environments often require additional techniques to improve retrieval accuracy, reduce hallucinations, enhance user experiences, and support more complex business workflows.
These advanced approaches help transform RAG from a simple question-answering system into a powerful enterprise AI platform.
Hybrid Search
Traditional RAG systems often rely exclusively on vector similarity search.
While semantic search is highly effective, it may occasionally miss critical information that contains exact keywords, identifiers, product names, or regulatory references.
Hybrid search combines:
-
Semantic search
-
Keyword search
This approach allows systems to benefit from both contextual understanding and exact-match retrieval.
Benefits include:
-
Improved retrieval accuracy
-
Better handling of technical terminology
-
Stronger search relevance
-
Reduced retrieval failures
Hybrid search has become a common feature in enterprise-grade RAG architectures.
Reranking
Retrieving relevant documents is only the first step.
Many systems retrieve multiple candidate results and then use reranking models to determine which content is most relevant to the user’s query.
Reranking helps:
-
Improve result quality
-
Reduce irrelevant context
-
Increase response accuracy
-
Improve user trust
In many enterprise environments, reranking delivers significant quality improvements without major architectural changes.
Query Expansion
Users often submit incomplete or ambiguous questions.
Query expansion enhances retrieval by generating additional search variations before retrieval occurs.
For example:
User Query:
How does onboarding work?
Expanded Retrieval Queries:
Employee onboarding process
New hire onboarding workflow
Staff onboarding policy
This technique helps systems retrieve more relevant information and improve overall response quality.
Metadata Filtering
Enterprise knowledge repositories frequently contain millions of documents.
Metadata filtering enables systems to narrow retrieval based on specific criteria such as:
-
Department
-
Region
-
Business unit
-
Document type
-
Publication date
-
Security classification
Filtering improves both retrieval efficiency and security.
It is particularly important for large organisations managing diverse knowledge repositories.
Multi-Step Retrieval
Some business questions require information from multiple sources.
Rather than performing a single retrieval operation, multi-step retrieval systems execute several retrieval stages before generating a response.
Benefits include:
-
Improved reasoning
-
Better context coverage
-
More comprehensive answers
-
Stronger support for complex workflows
This approach is increasingly used in enterprise research, compliance, and decision-support applications.
Agentic RAG
Agentic RAG combines retrieval systems with autonomous decision-making capabilities.
Rather than simply answering questions, the AI can:
-
Retrieve information
-
Evaluate options
-
Execute workflows
-
Call external tools
-
Complete multi-step tasks
This architecture is becoming increasingly important as organisations build advanced AI Agents capable of interacting with business systems and operational processes.
Graph RAG
Graph RAG extends traditional retrieval techniques by incorporating knowledge graphs and entity relationships.
Instead of retrieving information solely through similarity search, Graph RAG understands relationships between:
-
People
-
Organisations
-
Products
-
Documents
-
Events
-
Business entities
Benefits include:
-
Improved contextual understanding
-
Better reasoning capabilities
-
Stronger relationship discovery
-
Enhanced complex query handling
Graph-based approaches are gaining popularity in industries that manage highly interconnected information.
Context Compression
As knowledge repositories grow, retrieved context can become excessively large.
Context compression techniques help:
-
Reduce token usage
-
Improve response speed
-
Lower inference costs
-
Maintain response quality
This becomes particularly important when working with large enterprise document collections.
Evaluation and Continuous Improvement
One of the most overlooked aspects of advanced RAG systems is evaluation.
Successful organisations continuously measure:
-
Retrieval accuracy
-
Response quality
-
Citation relevance
-
User satisfaction
-
Hallucination rates
-
System performance
Evaluation frameworks help teams identify weaknesses and improve system quality over time.
Building Enterprise-Grade RAG Systems
Advanced RAG techniques are not always required during the initial stages of development.
However, as organisations scale AI initiatives, these capabilities often become essential for maintaining quality, accuracy, and user trust.
Many enterprise RAG Development projects begin with a relatively simple architecture and gradually introduce advanced retrieval, reranking, filtering, and agentic capabilities as requirements evolve.
The most successful systems are those that continuously improve retrieval quality while maintaining strong security, governance, and operational controls.
As enterprise AI adoption accelerates, advanced RAG techniques will increasingly differentiate production-ready AI systems from basic chatbot implementations.
RAG Development Technology Stack
Building a production-ready RAG system requires a carefully selected technology stack that supports retrieval, search, orchestration, security, scalability, and AI response generation.
While technology choices vary depending on project requirements, most enterprise RAG systems consist of several core layers working together to deliver accurate and reliable AI experiences.
The objective is not simply to connect a language model to company documents, but to create a secure, maintainable, and scalable platform capable of supporting long-term business needs.
Data Storage and Knowledge Sources
Enterprise knowledge is often distributed across multiple systems.
Common knowledge sources include:
-
Document repositories
-
Knowledge bases
-
CRM platforms
-
Databases
-
Internal portals
-
Product documentation
-
Cloud storage systems
The retrieval layer must be capable of accessing and processing information from these sources efficiently.
Embedding Models
Embedding models convert text into vector representations that can be searched semantically.
Popular options include:
-
OpenAI Embeddings
-
Voyage AI
-
BGE Models
-
E5 Models
-
Cohere Embeddings
The quality of embeddings directly influences retrieval accuracy and search relevance.
Selecting an appropriate embedding model is therefore a critical architectural decision.
Vector Database Layer
Vector databases store embeddings and power similarity search operations.
Popular technologies include:
-
Pinecone
-
Weaviate
-
Qdrant
-
Milvus
-
pgvector
These platforms enable fast retrieval of relevant information and serve as the foundation of the retrieval pipeline.
Many enterprise RAG Development projects rely on dedicated vector databases to support scalability and retrieval performance.
Large Language Model Layer
The language model layer is responsible for reasoning, summarisation, content generation, and natural language interaction.
Popular model providers include:
-
OpenAI
-
Anthropic
-
Google
-
Meta
-
Mistral
The optimal choice depends on factors such as performance requirements, deployment preferences, security considerations, and budget.
Many enterprise AI platforms also require robust LLM Integration capabilities to connect securely with commercial and open-source language models while maintaining reliability, scalability, and governance controls.
Orchestration Frameworks
Orchestration frameworks coordinate interactions between retrieval systems, vector databases, external tools, and language models.
Popular frameworks include:
-
LangChain
-
LlamaIndex
-
Haystack
These frameworks help developers manage:
-
Retrieval workflows
-
Prompt construction
-
Tool integration
-
Context management
-
Multi-step reasoning
As RAG architectures grow more sophisticated, orchestration becomes increasingly important.
Backend Application Layer
The backend layer manages business logic, APIs, security controls, and system integrations.
Enterprise RAG systems commonly use technologies such as:
-
NestJS
-
Node.js
-
Python
-
FastAPI
-
.NET
Responsibilities typically include:
-
Authentication
-
Access control
-
Document ingestion
-
Workflow management
-
Audit logging
-
System integrations
A well-designed backend architecture helps ensure reliability and maintainability.
Frontend and User Experience Layer
Users interact with RAG systems through web applications, portals, chat interfaces, and internal platforms.
Popular frontend technologies include:
-
Next.js
-
React
-
TypeScript
-
Tailwind CSS
The user experience layer should prioritise:
-
Fast responses
-
Source visibility
-
Accessibility
-
Mobile compatibility
-
Enterprise usability
A powerful retrieval system provides limited value if users struggle to access information effectively.
Security and Governance Layer
Enterprise deployments require comprehensive security controls.
Common security components include:
-
Single Sign-On (SSO)
-
Multi-Factor Authentication (MFA)
-
Role-Based Access Control (RBAC)
-
Encryption
-
Audit logging
-
Data governance policies
Security should be integrated into every layer of the architecture rather than treated as a separate feature.
Monitoring and Observability
Production AI systems require continuous monitoring.
Important metrics often include:
-
Retrieval quality
-
Response accuracy
-
Latency
-
System availability
-
User satisfaction
-
Infrastructure health
Monitoring enables teams to identify issues early and maintain system reliability as adoption grows.
A Typical Enterprise RAG Stack
While implementations vary, a common enterprise architecture may include:
-
Next.js for frontend applications
-
NestJS for backend services
-
OpenAI or Anthropic models
-
Qdrant or Pinecone for vector search
-
PostgreSQL for operational data
-
LangChain or LlamaIndex for orchestration
-
Cloud infrastructure for scalability and resilience
This combination provides a strong foundation for building secure and scalable enterprise AI systems.
Choosing the Right Technology Stack
Technology decisions should be guided by business objectives rather than trends.
Factors to consider include:
-
Security requirements
-
Compliance obligations
-
Scalability expectations
-
Deployment preferences
-
Budget constraints
-
Existing infrastructure
The most effective RAG architectures are those that align technology choices with long-term business goals rather than short-term experimentation.
As enterprise AI adoption continues to accelerate, organisations investing in AI Development initiatives must ensure their technology stack can support long-term growth, security, and operational requirements.
RAG Development Cost
One of the most common questions organisations ask when evaluating enterprise AI initiatives is:
“How much does RAG development cost?”
The answer depends on several factors, including project complexity, data volume, security requirements, system integrations, deployment architecture, and overall business objectives.
A simple proof-of-concept may be relatively inexpensive, while a fully integrated enterprise platform supporting thousands of users, multiple knowledge sources, and advanced governance controls requires significantly greater investment.
Understanding the major cost drivers can help organisations plan budgets more effectively and make informed technology decisions.
Factors That Influence RAG Development Cost
Several variables influence the total cost of a RAG project.
Common considerations include:
-
Number of knowledge sources
-
Data volume
-
Security requirements
-
Compliance obligations
-
System integrations
-
User access controls
-
AI model selection
-
Vector database infrastructure
-
Monitoring and observability requirements
-
Deployment architecture
Projects with strict governance requirements and complex enterprise integrations typically require additional engineering effort.
Proof of Concept (PoC)
Many organisations begin with a proof-of-concept to validate business value before committing to larger investments.
Typical objectives include:
-
Demonstrating retrieval quality
-
Testing user adoption
-
Validating business use cases
-
Assessing technical feasibility
A proof-of-concept generally focuses on a limited dataset and a small user group.
Typical investment:
USD 5,000 – USD 15,000
Typical timeline:
2–4 weeks
MVP RAG Platform
An MVP introduces production-oriented capabilities while maintaining a focused scope.
Typical features include:
-
Knowledge ingestion
-
Vector search
-
Chat interface
-
Basic authentication
-
Source attribution
-
Limited integrations
The objective is to create a usable system that can be evaluated by real users.
Typical investment:
USD 15,000 – USD 40,000
Typical timeline:
4–8 weeks
Growth-Stage Enterprise Platform
As adoption expands, organisations often require additional functionality and governance controls.
Common additions include:
-
Multiple knowledge repositories
-
Advanced retrieval pipelines
-
Role-based access controls
-
Monitoring and analytics
-
Workflow integrations
-
API access
-
Department-specific knowledge environments
Typical investment:
USD 40,000 – USD 100,000+
Typical timeline:
2–4 months
Enterprise AI Knowledge Platform
Large-scale deployments often require extensive architecture, governance, and operational capabilities.
Features may include:
-
Multi-department knowledge systems
-
Advanced security controls
-
Compliance workflows
-
Hybrid search
-
Reranking
-
Agentic workflows
-
High-availability infrastructure
-
Enterprise integrations
Typical investment:
USD 100,000 – USD 500,000+
Typical timeline:
4–12+ months
Infrastructure and Operational Costs
In addition to development costs, organisations should consider ongoing operational expenses.
Examples include:
-
AI model usage
-
Vector database hosting
-
Cloud infrastructure
-
Storage
-
Monitoring systems
-
Security services
-
Maintenance and support
Operational costs vary significantly depending on usage volume, architecture choices, and deployment scale.
Build vs Buy Considerations
Some organisations evaluate managed AI platforms before pursuing custom development.
Managed solutions can reduce implementation effort but may introduce limitations related to:
-
Customisation
-
Data ownership
-
Security controls
-
Scalability
-
Vendor dependency
Custom RAG Development typically requires a larger initial investment but provides greater flexibility and long-term control.
Cost Optimisation Strategies
Organisations can often reduce costs by:
-
Starting with a focused use case
-
Prioritising high-value knowledge sources
-
Using phased implementation plans
-
Selecting appropriate infrastructure
-
Measuring adoption early
-
Expanding gradually based on business value
A phased approach frequently delivers stronger outcomes than attempting to build a large enterprise platform from the beginning.
Return on Investment
The value of a RAG system is not measured solely by implementation cost.
Successful deployments often generate returns through:
-
Faster information access
-
Reduced support workloads
-
Improved employee productivity
-
Better customer experiences
-
Reduced operational inefficiencies
-
Stronger knowledge management
For many organisations, these benefits can significantly outweigh the initial investment over time.
Investing in Long-Term AI Infrastructure
RAG systems are increasingly becoming part of the core technology infrastructure supporting enterprise AI initiatives.
Many organisations now view these platforms as strategic investments within broader AI Development programmes.
As organisations expand their use of AI across departments and workflows, investing in a secure and scalable architecture often delivers greater long-term value than focusing solely on initial implementation costs.
For businesses evaluating RAG Development, the objective should be to build a platform that supports future growth, governance requirements, and evolving business needs rather than simply minimising upfront expenditure.
Development Timeline
The timeline for building a RAG system depends on several factors, including project scope, data complexity, security requirements, integration needs, and overall business objectives.
While simple proof-of-concepts can often be developed relatively quickly, enterprise-grade deployments require careful planning, architecture design, security implementation, testing, and operational readiness.
Successful organisations typically follow a phased approach that reduces risk while ensuring the system can scale effectively over time.
Phase 1: Discovery and Planning
Every successful RAG initiative begins with understanding business requirements and defining success criteria.
Activities typically include:
-
Stakeholder workshops
-
Use case identification
-
Knowledge source assessment
-
Security requirements analysis
-
Architecture planning
-
Technology selection
-
Project roadmap creation
This phase establishes the foundation for all future development work.
Typical duration:
1–3 weeks
Phase 2: Data Assessment and Knowledge Preparation
Before retrieval systems can operate effectively, organisations must evaluate and prepare their knowledge sources.
Common activities include:
-
Document analysis
-
Data quality assessment
-
Metadata review
-
Content classification
-
Knowledge source mapping
-
Governance planning
The objective is to ensure that the retrieval layer can access high-quality and trustworthy information.
Typical duration:
1–4 weeks
Phase 3: Architecture and Infrastructure Setup
This phase focuses on establishing the technical foundation of the platform.
Activities may include:
-
Cloud infrastructure setup
-
Vector database deployment
-
Security configuration
-
Identity management integration
-
Development environment preparation
-
Monitoring setup
A strong architecture reduces future operational and scalability challenges.
Typical duration:
1–3 weeks
Phase 4: Core RAG Development
This is typically the largest phase of the project.
Development activities often include:
-
Document ingestion pipelines
-
Embedding generation
-
Vector search implementation
-
Retrieval workflows
-
Prompt engineering
-
LLM integration
-
User interface development
-
API development
The complexity of this phase varies significantly depending on project requirements and integration needs.
Typical duration:
4–10 weeks
Phase 5: Security and Governance Implementation
Enterprise deployments require comprehensive security controls and governance frameworks.
Activities may include:
-
Authentication integration
-
Role-based access controls
-
Document-level permissions
-
Audit logging
-
Encryption implementation
-
Compliance controls
-
Security testing
Security should be integrated throughout development, but dedicated validation often occurs before production deployment.
Typical duration:
1–4 weeks
Phase 6: Testing and Evaluation
Before launch, organisations should thoroughly evaluate both retrieval quality and user experience.
Common testing activities include:
-
Retrieval accuracy testing
-
Response quality evaluation
-
Security validation
-
Performance testing
-
User acceptance testing
-
Governance reviews
This phase helps ensure that the system performs reliably in real-world environments.
Typical duration:
2–4 weeks
Phase 7: Production Deployment and Rollout
The final stage focuses on operational readiness and user adoption.
Activities often include:
-
Production deployment
-
Monitoring configuration
-
Knowledge source synchronisation
-
User training
-
Support preparation
-
Performance monitoring
A structured rollout approach helps reduce operational risk and improve adoption rates.
Typical duration:
1–3 weeks
Typical Project Timelines
While every organisation has unique requirements, the following ranges are common:
Proof of Concept
Focused validation using a limited dataset and a small user group.
Estimated timeline: 2–6 weeks
MVP RAG Platform
Production-oriented deployment with core retrieval and AI capabilities.
Estimated timeline: 1–3 months
Growth-Stage Enterprise Platform
Expanded integrations, governance controls, and broader organisational adoption.
Estimated timeline: 3–6 months
Enterprise AI Knowledge Platform
Large-scale deployment supporting multiple departments, knowledge repositories, and advanced AI workflows.
Estimated timeline: 6–12+ months
Factors That Influence Timelines
Several factors can accelerate or extend delivery schedules.
Common considerations include:
-
Number of knowledge sources
-
Data quality
-
Security requirements
-
Compliance obligations
-
Integration complexity
-
User access requirements
-
Infrastructure architecture
-
Organisational readiness
Projects involving highly regulated environments or complex enterprise systems typically require additional planning and validation.
Why a Phased Approach Works Best
Many organisations attempt to launch large AI initiatives all at once.
In practice, phased delivery often produces better outcomes.
A phased approach enables teams to:
-
Validate business value early
-
Improve retrieval quality incrementally
-
Reduce implementation risk
-
Gather user feedback
-
Scale confidently
This approach is widely used in successful RAG Development programmes because it balances innovation with operational stability.
Building for Long-Term Success
The goal of a RAG project should not simply be to launch quickly.
Long-term success depends on building a secure, scalable, and maintainable platform capable of supporting future growth.
Organisations that invest in planning, governance, security, and evaluation often achieve better outcomes than those focused solely on rapid deployment.
As enterprise AI adoption continues to accelerate, realistic timelines and structured implementation strategies remain essential for delivering sustainable business value.
Common Mistakes in RAG Development
Many organisations begin their AI journey with significant enthusiasm and ambitious expectations.
However, while Retrieval-Augmented Generation has become one of the most effective approaches for enterprise AI, successful implementation requires more than simply connecting a language model to a vector database.
In practice, many projects encounter challenges related to retrieval quality, security, governance, user adoption, and operational scalability.
Understanding these common mistakes can help organisations reduce risk and improve the likelihood of long-term success.
Treating RAG as a Simple Chatbot Project
One of the most common misconceptions is viewing RAG as nothing more than a chatbot connected to company documents.
While simple prototypes can often be built quickly, enterprise systems require:
-
Security controls
-
Governance frameworks
-
Knowledge management processes
-
Monitoring systems
-
Access control policies
-
Operational support
Successful RAG implementations should be treated as enterprise platforms rather than standalone chat applications.
Poor Knowledge Source Selection
A RAG system can only be as effective as the information it retrieves.
Many projects attempt to ingest large volumes of content without evaluating quality, relevance, or accuracy.
Common issues include:
-
Outdated documents
-
Duplicate content
-
Incomplete information
-
Inconsistent formatting
-
Poor metadata quality
Retrieval systems perform best when they are built on trusted and well-maintained knowledge sources.
Incorrect Chunking Strategies
Chunking is one of the most overlooked aspects of retrieval engineering.
If document chunks are too large, retrieval quality may suffer because irrelevant information is returned.
If chunks are too small, important context may be lost.
Finding the right balance is essential for maintaining retrieval accuracy and response quality.
Well-designed chunking strategies often have a greater impact on performance than many organisations initially expect.
Focusing Only on the Language Model
Many teams spend significant time selecting a language model while paying insufficient attention to retrieval quality.
In reality, retrieval performance often has a greater influence on user satisfaction than model selection.
Even highly capable models will generate poor responses if the retrieved context is incomplete, inaccurate, or irrelevant.
Successful RAG Development projects prioritise retrieval engineering alongside model selection.
Ignoring Security Requirements
Security is sometimes treated as a later-stage concern.
This can create significant risks when systems access sensitive business information.
Common security oversights include:
-
Weak access controls
-
Missing audit logs
-
Insufficient encryption
-
Poor governance policies
-
Excessive data exposure
Security should be incorporated into architecture and implementation decisions from the beginning.
Neglecting Document-Level Permissions
Enterprise knowledge repositories rarely contain information that should be accessible to everyone.
Without proper permission enforcement, users may retrieve information outside their authorised scope.
Examples include:
-
HR records
-
Financial reports
-
Legal agreements
-
Executive communications
Document-level access controls are essential for protecting sensitive information and maintaining trust.
Skipping Evaluation and Testing
Some organisations focus heavily on development but invest little time in evaluating system performance.
Without evaluation frameworks, teams often struggle to measure:
-
Retrieval accuracy
-
Response quality
-
Citation relevance
-
Hallucination rates
-
User satisfaction
Continuous evaluation is critical for maintaining quality as knowledge repositories and business requirements evolve.
Underestimating Knowledge Maintenance
Knowledge repositories are constantly changing.
Policies, procedures, documentation, and operational information must be updated regularly.
A common mistake is assuming that knowledge ingestion is a one-time activity.
In reality, successful systems require ongoing:
-
Content updates
-
Index refreshes
-
Metadata management
-
Quality reviews
Maintaining knowledge quality is essential for long-term success.
Overlooking User Experience
Technical performance alone does not guarantee adoption.
Users expect systems that are:
-
Easy to use
-
Fast
-
Transparent
-
Reliable
Features such as source attribution, clear citations, intuitive interfaces, and responsive interactions often influence adoption more than technical architecture alone.
Building Everything at Once
Many organisations attempt to deploy large-scale enterprise AI systems immediately.
This can introduce unnecessary complexity and increase project risk.
A more effective approach is often to:
-
Start with a focused use case
-
Validate business value
-
Gather feedback
-
Improve retrieval quality
-
Expand gradually
Phased delivery typically produces stronger long-term outcomes than attempting to solve every problem simultaneously.
Learning from Common Challenges
Most RAG implementation issues are not caused by the technology itself.
They are usually the result of planning decisions, knowledge management challenges, governance gaps, or unrealistic expectations.
Organisations that focus on retrieval quality, security, governance, evaluation, and user adoption are significantly more likely to achieve successful outcomes.
As enterprise AI adoption continues to grow, avoiding these common mistakes will become increasingly important for building reliable, scalable, and trusted AI systems.
Why Most Enterprise AI Projects Fail
Enterprise interest in artificial intelligence continues to grow rapidly.
Organisations across industries are investing in AI to improve productivity, enhance customer experiences, automate workflows, and gain competitive advantages.
Despite this momentum, many enterprise AI initiatives fail to achieve meaningful business outcomes.
In most cases, failure is not caused by the AI model itself.
Instead, projects often struggle because of planning, governance, adoption, data quality, and organisational challenges.
Understanding these factors can help organisations build AI systems that deliver sustainable value rather than short-term experimentation.
Lack of a Clear Business Objective
One of the most common reasons AI projects fail is the absence of a clearly defined business problem.
Many organisations begin with questions such as:
-
How can we use AI?
-
Which model should we choose?
-
What AI tools are trending?
These questions focus on technology rather than business outcomes.
Successful projects typically begin with objectives such as:
-
Reducing support costs
-
Improving employee productivity
-
Accelerating knowledge discovery
-
Enhancing customer experiences
-
Streamlining compliance workflows
Clear objectives create measurable outcomes and improve project alignment.
Treating AI as a Technology Experiment
Some organisations approach AI as an isolated innovation initiative rather than a business capability.
This often results in:
-
Limited adoption
-
Poor integration
-
Unclear ownership
-
Lack of long-term support
AI systems generate the greatest value when they become integrated into existing workflows and operational processes.
Poor Data Quality
AI systems depend heavily on data quality.
Even sophisticated architectures can produce poor results when knowledge sources contain:
-
Outdated information
-
Duplicate content
-
Incomplete records
-
Inconsistent formatting
-
Low-quality documentation
Many AI initiatives underestimate the importance of knowledge management and data governance.
Insufficient Executive Sponsorship
Enterprise AI initiatives often require collaboration across multiple departments.
Without executive support, projects may encounter:
-
Resource constraints
-
Organisational resistance
-
Competing priorities
-
Delayed decision-making
Leadership involvement helps ensure alignment between technical implementation and business objectives.
Ignoring Security and Governance
As AI adoption expands, security and governance become increasingly important.
Projects that overlook these areas may face challenges related to:
-
Data protection
-
Access control
-
Regulatory compliance
-
Auditability
-
Operational risk
Trust is essential for enterprise adoption.
Users are unlikely to embrace AI systems if they lack confidence in security and governance controls.
Unrealistic Expectations
AI technologies are powerful, but they are not a universal solution.
Some organisations expect AI to immediately solve every operational challenge.
This can lead to disappointment when systems encounter:
-
Data limitations
-
Business process constraints
-
Knowledge gaps
-
User adoption challenges
Successful organisations typically adopt a phased approach focused on continuous improvement rather than immediate transformation.
Weak Change Management
Introducing AI often changes how people access information and perform tasks.
Without proper change management, users may:
-
Resist adoption
-
Distrust outputs
-
Continue using legacy processes
-
Ignore new capabilities
Training, communication, and stakeholder engagement play an important role in successful AI deployment.
Failure to Measure Success
Many projects launch without defining measurable success criteria.
Without metrics, organisations struggle to evaluate:
-
User adoption
-
Productivity improvements
-
Support reductions
-
Operational efficiencies
-
Return on investment
Successful initiatives typically establish clear KPIs before deployment begins.
Building AI Without Business Integration
Some organisations create technically impressive AI systems that remain disconnected from business workflows.
As a result, users gain limited practical value.
Enterprise AI systems are most effective when integrated with:
-
Internal knowledge systems
-
Customer support platforms
-
Business applications
-
Compliance workflows
-
Operational processes
Integration often determines whether AI becomes a strategic capability or an unused experiment.
Why Enterprise RAG Projects Succeed
Many organisations are increasingly adopting RAG Development architectures because they address several of the challenges that have historically limited enterprise AI success.
By connecting language models to trusted organisational knowledge, RAG systems help improve:
-
Accuracy
-
Explainability
-
Security
-
Governance
-
User trust
This alignment between AI capabilities and business knowledge creates a stronger foundation for long-term adoption.
Building Sustainable AI Programmes
The most successful enterprise AI initiatives are rarely those that move the fastest.
They are often the organisations that invest in:
-
Clear business objectives
-
High-quality knowledge sources
-
Strong governance
-
Security controls
-
User adoption strategies
-
Continuous improvement
Technology remains important, but sustainable success ultimately depends on how effectively AI is aligned with business needs and organisational goals.
As enterprise AI adoption continues to mature, organisations investing in AI Development initiatives will be better positioned to realise long-term value from their investments.
Choosing the Right RAG Development Company
Selecting the right development partner is one of the most important decisions in any enterprise AI initiative.
The quality of the development team can significantly influence system accuracy, security, scalability, maintainability, and long-term business value.
While many organisations now offer AI services, building production-ready RAG systems requires expertise that extends beyond chatbot development and prompt engineering.
Enterprise RAG platforms combine retrieval systems, vector databases, security controls, governance frameworks, orchestration layers, and large language models into a single architecture.
As a result, choosing a development partner should involve more than comparing project costs or technology stacks.
Look for Enterprise AI Experience
Enterprise AI projects present unique challenges that differ significantly from traditional software development.
A qualified development partner should understand:
-
Enterprise AI architectures
-
Knowledge management systems
-
Retrieval engineering
-
Governance requirements
-
Security controls
-
Operational scalability
Many organisations begin their journey through broader AI Development initiatives before expanding into enterprise RAG platforms and knowledge systems.
Experience with real-world deployments often helps reduce implementation risks and improve project outcomes.
Evaluate RAG Architecture Expertise
Building an effective RAG system requires expertise across multiple technical domains.
Areas to evaluate include:
-
Data ingestion pipelines
-
Embedding strategies
-
Vector databases
-
Retrieval optimisation
-
Prompt engineering
-
Evaluation frameworks
-
Security architecture
Strong LLM Integration practices are also important for ensuring reliable connectivity, governance, and performance across multiple AI model providers.
The ability to design and maintain high-quality retrieval systems is often more important than simply integrating a language model.
Security Should Be a Core Competency
Enterprise AI systems frequently interact with sensitive organisational information.
When evaluating potential partners, consider their approach to:
-
Authentication
-
Access controls
-
Document permissions
-
Encryption
-
Audit logging
-
Compliance requirements
Security should be integrated into architecture decisions from the beginning rather than treated as a later-stage enhancement.
Assess Integration Capabilities
Enterprise AI systems rarely operate in isolation.
A development company should be capable of integrating RAG platforms with:
-
CRM systems
-
Knowledge bases
-
Internal portals
-
Business applications
-
Cloud infrastructure
-
Identity providers
Strong integration capabilities help ensure the platform delivers value across the organisation.
Understand Their Approach to Governance
Governance is becoming increasingly important as AI adoption expands.
A capable RAG Development company should understand:
-
Data governance
-
Compliance controls
-
Access management
-
Audit requirements
-
Operational policies
Governance frameworks help organisations deploy AI responsibly while reducing operational and regulatory risks.
Evaluate Scalability Planning
Many AI projects begin with a limited user group before expanding across departments.
Development partners should demonstrate experience with:
-
Infrastructure scalability
-
Performance optimisation
-
Knowledge growth
-
User growth
-
Operational monitoring
The architecture should support future expansion without requiring major redesign efforts.
Ask About Evaluation Methodologies
One of the most important indicators of expertise is how a development company evaluates AI quality.
Questions to ask include:
-
How is retrieval quality measured?
-
How are hallucinations monitored?
-
What evaluation frameworks are used?
-
How is response quality validated?
-
How is user feedback incorporated?
Organisations that prioritise evaluation are generally better positioned to deliver reliable enterprise AI systems.
Look Beyond Initial Development Costs
Cost is an important consideration, but it should not be the only factor influencing vendor selection.
The lowest-cost option may result in:
-
Weak retrieval performance
-
Security gaps
-
Scalability limitations
-
Governance challenges
-
Increased long-term maintenance costs
The objective should be to maximise long-term value rather than minimise initial expenditure.
Questions to Ask Before Selecting a Partner
Before choosing a RAG Development company, consider asking:
-
What enterprise AI projects have you delivered?
-
How do you approach retrieval optimisation?
-
Which vector databases do you recommend and why?
-
How do you manage security and governance?
-
What evaluation frameworks do you use?
-
How do you support long-term scalability?
-
What post-launch support options are available?
These questions can provide valuable insight into the company’s expertise and delivery approach.
Building a Long-Term AI Partnership
Successful AI initiatives rarely end at launch.
As knowledge repositories grow, business requirements evolve, and AI capabilities advance, organisations often require continuous optimisation and support.
The most effective development partners act as long-term collaborators, helping businesses improve retrieval quality, strengthen governance controls, enhance user experiences, and scale AI adoption over time.
For organisations investing in RAG Development, choosing the right partner can significantly influence both the success of the initial deployment and the long-term value generated from enterprise AI initiatives.
Frequently Asked Questions
What is RAG in AI?
RAG stands for Retrieval-Augmented Generation.
It is an AI architecture that combines large language models with external knowledge retrieval systems. Instead of relying solely on training data, a RAG system retrieves relevant information from trusted knowledge sources before generating a response.
This approach helps improve accuracy, reduce hallucinations, and provide access to current business information.
How is RAG different from fine-tuning?
Fine-tuning modifies a model’s behaviour by training it on additional data.
RAG, on the other hand, retrieves relevant information at query time and provides that context to the model before generating a response.
Many organisations prefer RAG because it allows knowledge to be updated without retraining the model and provides greater transparency regarding information sources.
Why is RAG important for enterprise AI?
Enterprise environments require AI systems that can access private organisational knowledge while maintaining accuracy, security, and governance controls.
RAG enables organisations to connect AI models with internal documentation, policies, procedures, knowledge bases, and business systems.
This makes it particularly well suited for enterprise AI applications where information changes frequently.
What types of data can a RAG system use?
Modern RAG systems can retrieve information from a wide range of sources, including:
-
PDF documents
-
Knowledge bases
-
Internal portals
-
CRM systems
-
Databases
-
Product documentation
-
Cloud storage platforms
-
Customer support repositories
The specific sources depend on business requirements and integration capabilities.
Which vector database is best for RAG?
There is no universal answer.
The best option depends on factors such as scalability requirements, deployment preferences, infrastructure expertise, and budget.
Common choices include:
-
Pinecone
-
Weaviate
-
Qdrant
-
pgvector
Each platform offers different advantages depending on project requirements.
How secure are enterprise RAG systems?
A properly designed RAG system can provide strong security controls, including:
-
Authentication
-
Role-based access control
-
Document-level permissions
-
Encryption
-
Audit logging
-
Governance frameworks
Security should be incorporated throughout the architecture rather than added after deployment.
Can RAG systems work with private company data?
Yes.
One of the primary advantages of RAG is its ability to retrieve information from private organisational knowledge sources.
Many enterprises use RAG to provide secure access to internal documentation, operational procedures, policies, and business knowledge while maintaining access controls.
How much does RAG development cost?
The cost of RAG development depends on project complexity, integrations, security requirements, data volume, and scalability needs.
Typical investment ranges include:
-
Proof of Concept: USD 5,000–15,000
-
MVP Platform: USD 15,000–40,000
-
Growth-Stage Platform: USD 40,000–100,000+
-
Enterprise Deployment: USD 100,000–500,000+
Actual costs vary depending on business requirements and implementation scope.
How long does it take to build a RAG system?
Timelines vary depending on project complexity and organisational requirements.
Typical ranges include:
-
Proof of Concept: 2–6 weeks
-
MVP Platform: 1–3 months
-
Growth-Stage Platform: 3–6 months
-
Enterprise Deployment: 6–12+ months
A phased approach is generally recommended to reduce risk and improve adoption.
What should I look for in a RAG Development company?
Key considerations include:
-
Enterprise AI experience
-
Retrieval engineering expertise
-
Security capabilities
-
Governance knowledge
-
Integration experience
-
Evaluation methodologies
-
Long-term support options
Choosing an experienced development partner can significantly improve the likelihood of project success and long-term business value.
Additional Resources
For further reading on enterprise AI and retrieval-augmented generation, review:
OpenAI — Documentation for models, embeddings, and AI application development.
Anthropic — Guidance on enterprise AI, Claude models, and responsible AI deployment.
Pinecone — Vector database resources for retrieval-augmented generation systems.
Final Thoughts
Artificial intelligence is rapidly transforming how organisations access information, automate workflows, and support decision-making.
However, as enterprise adoption grows, businesses increasingly recognise that standalone language models are not enough. Accuracy, security, governance, and access to organisational knowledge have become critical requirements for production AI systems.
This is why Retrieval-Augmented Generation has emerged as one of the most important enterprise AI architectures.
Throughout this guide, we explored the principles of RAG Development, including architecture design, vector databases, retrieval systems, security considerations, technology stacks, implementation costs, development timelines, and best practices.
While the technology continues to evolve, the core objective remains the same: connecting AI capabilities with trusted business knowledge.
Organisations that invest in strong retrieval architectures, governance frameworks, and long-term operational planning are better positioned to build AI systems that users trust and rely on every day.
Whether you are building an internal knowledge assistant, enterprise search platform, customer support solution, compliance system, or AI-powered SaaS product, a well-designed RAG architecture can provide the foundation for scalable and sustainable AI adoption.
As enterprise AI continues to mature, RAG Development will remain a critical capability for organisations seeking to move beyond experimentation and create measurable business value from artificial intelligence investments.

